隨著 Google 在3月21日發佈 Bard 後,很快的在網上看到許多人拿它與 ChatGPT 做比較,可能是因為比較的方法、題目不同等因素,造成結果不同,有人說 Bard 厲害,也有人說 ChatGPT 勝出,莫衷一是。本文重點摘譯 Search Engine Land 的一篇文章,它有比較具體的評比項目,結論如何請往下看。

圖片來源:searchengineland.com
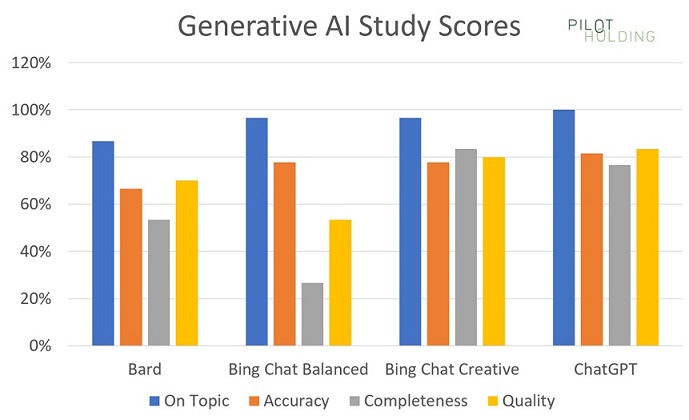
這篇文章比較了ChatGPT、Google Bard和Bing Chat,這些工具都被要求回答相同的30個問題,並根據主題(On-topic)、準確性(Accuracy)、完整性(Completeness)和品質(Quality)等指標進行評分。結果顯示:
- OpenAI在準確度方面表現最佳,81.5% 的時間提供了 100% 準確的回答。(這仍然表示它在近五分之一的回答中有事實錯誤。)
- Google Bard 的準確率為 63%,這表示其回答中有超過三分之一的資訊是不正確的。
- 基於 Bing 的兩種解決方案在 77.8% 的時間內是無錯誤的,這表示它們在近四分之一的回答中有不正確的資訊。
- 在完整性方面,沒有任何一種解決方案有超過50%的回答得到了完美的得分。然而,如果考慮完美得分和近乎完美得分的總和,則OpenAI提供了非常可靠的回答,超過四分之三的時間都能夠做到這一點。Bing Creative也並不遜色。但是,這意味著這些工具在四分之一或更多的時間內都有重大遺漏。
- ChatGPT 在 30 次測試中有 11 次得到完美分數。所有四個指標(主題、準確性、完整性和品質)都獲得了 1 分。Bing Creative 的完美分數次數排名第二,30 次測試中有 9 次得到完美分數。
圖片來源:searchengineland.com
作者特別強調其研究範圍僅限於 30 個問題,如果測試1,000個查詢,結果可能會有所不同。即便是相同的問題,可能每個人得到的結果也不同。儘管如此,他的結論如下:
ChatGPT 總體得分最高,稍微超過了 Bing Chat Creative。 Bing Chat Balanced 在許多情況下沒有提供足夠的細節,並且在完整性得分方面表現不佳,因此排名第三。 最新的參與者 Bard 在我們的研究中得分第四。
最後作者也說了,目前仍然處於這項技術的非常早期階段,未來在很多方面都會有快速的變化和進步。三家供應商都將繼續大力投資,推進他們的生成式 AI 工具。他相信 Google 感到了壓力,將盡可能努力彌補差距。
全文詳細內容請參見下方連結。
延伸閱讀:
Search Engine Land — ChatGPT vs. Google Bard vs. Bing Chat: Which generative AI solution is best?


發表留言